Code Is the Wrong Abstraction for AI
Better models won't fix a structural problem. The format has to change.

66% of developers spend more time fixing AI-generated code than they would writing it themselves. Not because the models are bad. Because code is the wrong format.
Every major AI coding tool optimizes for the same thing: generate more code, faster. Cursor, Copilot, Bolt, Lovable — they all produce React components, Express endpoints, CSS files. The output improves every quarter. The maintenance burden grows faster. An LLM produces 1,200 lines of JSX for a dashboard. Two sprints later, React deprecates the hook it used, a library renames its props, the bundle white-screens. Nobody owns the code.
When humans create legacy, we call it tech debt. When LLMs accelerate it, we get something worse: tech inflation. Exponentially growing technical debt with no owner and no plan.
Enterprise GenAI spending hit $37 billion in 2025, growing 3.2x year-over-year. 57% of companies run AI agents in production. But predominantly for isolated tasks: summarization, Q&A, document extraction. Almost none integrate agents into governed business processes with real UIs.
The reason is structural.
What code costs an AI
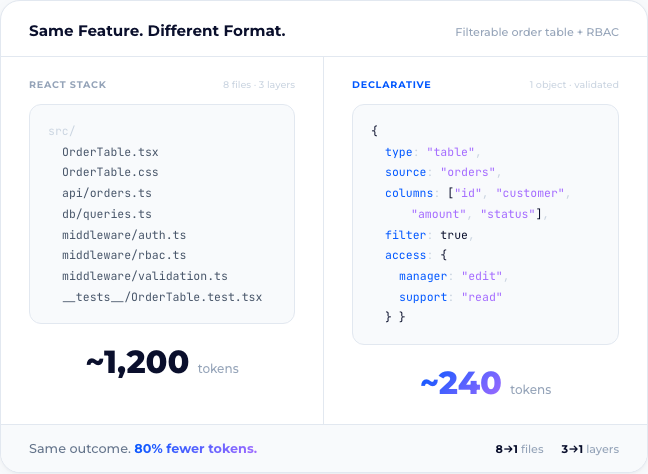
A screen that displays customer orders in a filterable table. Edit rights for managers, read-only for support staff.
In a React stack: a frontend component, a CSS file, an API endpoint, a database query, authentication middleware, role-based access logic, input validation, and tests. Eight files. Three layers.
In a declarative definition: one structured object describing the table, its columns, its data source, and its access rules.
Most of those eight files exist for human readability. Imports, type annotations, logging wrappers, naming conventions, comments explaining what the next line does. For an AI paying per token, every line is cost. The declarative version carries 50–80% fewer tokens for the same business outcome.
Fewer tokens isn’t a nice-to-have. On LongCodeBench (a benchmark testing coding LLMs on real-world GitHub tasks at up to 1M context windows), Claude 3.5 Sonnet’s bug-fix accuracy drops from 29% to 3% as input grows from 32K to 256K tokens.1 Feed a model eight files and it starts hallucinating. Feed it one structured definition and it stays precise.
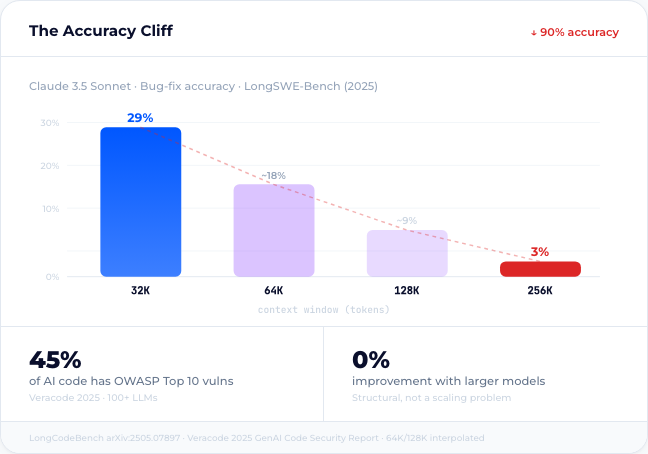
Veracode tested 100+ LLMs across 80 coding tasks in 2025. In 45% of test cases, the generated code contained OWASP Top 10 vulnerabilities: cross-site scripting, log injection, access control failures.2 Not edge cases. The standard vulnerability classes that enterprises already spend millions to prevent. The failure rate didn’t improve with model size. This is structural, not a scaling problem.
For an internal chatbot summarizing meeting notes, that’s tolerable risk. For the ERP workflow that processes purchase orders at enterprise scale, it’s not.
When code works
Code as AI output can work. The conditions are specific.
Static typing catches shape errors at compile time. Linters enforce style and safety rules. CI/CD pipelines run tests on every commit. SAST and DAST scanners flag known vulnerability patterns before deployment. Code review, policy-as-code, and dependency audits close the remaining gaps.
Under these conditions, AI-generated code enters a system that catches most defects before they reach production. The toolchain works — when it’s maintained by engineers who understand what each layer does and why it’s there.
That “when” is load-bearing. The full stack of safeguards requires senior-level discipline, consistent enforcement, and organizational willingness to invest in infrastructure that doesn’t ship features. For a well-funded engineering team building a core product, that investment pays off. The question is whether that describes the majority of software being built — or a shrinking minority.
Why this doesn’t scale in organizations
The gap widens when organizations push software creation beyond the engineering team. Business analysts, operations staff, domain experts. The people closest to the problem, furthest from the toolchain.
This is the reality of “vibe coding” in enterprises. Not a solo developer prototyping a weekend project, but non-engineers generating production-adjacent code through AI tools. The safety net collapses:
- No review capability. A business analyst can’t assess whether generated React state management creates race conditions.
- Proliferation without governance. Each team builds isolated apps with different patterns, frameworks, and data access methods. No shared architecture. No shared standards.
- Unclear ownership. When the generated app breaks at 2 AM, no one owns the code — because no one wrote it.
- Security and compliance gaps. Without SAST integration and review processes, generated code with OWASP vulnerabilities ships to production. Veracode’s 45% failure rate applies doubly when there’s no engineer reviewing the output.
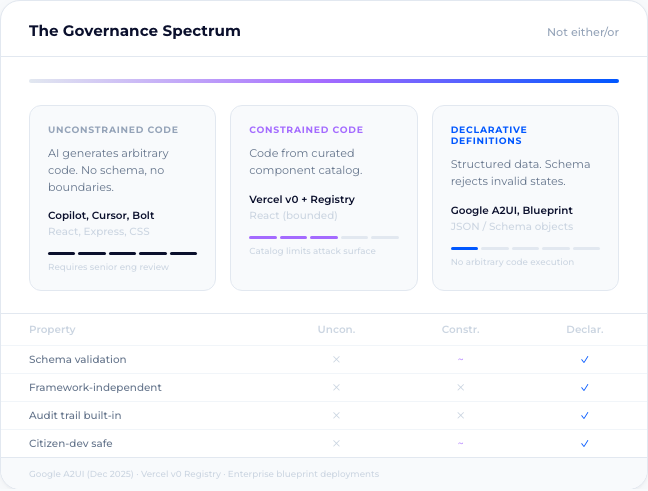
This isn’t anti-code. It’s recognizing that uncontrolled code generation doesn’t work as an org-wide self-service model. For organization-wide customization and workflow building, you need constraints: validated schemas, role-based permissions, pre-approved building blocks. Not “generate anything” — “compose from governed components.”
Better models won’t fix this
A common rebuttal: AI will keep improving at writing code. It will. But better generation doesn’t fix a structural problem.
Code is unbounded. There’s no schema constraining what an LLM can produce. It’s framework-dependent: tied to React 18 today, broken by React 19 tomorrow. It’s scattered across files, layers, and conventions that exist to help human brains navigate complexity.
Every improvement in generation creates more code to maintain. The codebase gets bigger. The context window fills faster. Accuracy drops. The review burden grows. In organizations without deep engineering discipline, no one picks it up.
The problem isn’t the quality of the code. It’s that code is the wrong abstraction for machine-to-machine collaboration. What’s needed is a bounded, schema-validated, framework-independent representation. That’s a category difference, not a quality difference.
A faster typewriter doesn’t become a word processor.
What “post-code” looks like
Declarative definitions. Structured data that describes what an application does without prescribing how it’s implemented. A schema enforces validity at write time: an AI agent or a human cannot persist an invalid state. Errors that would surface weeks later in a code-based system get rejected before they’re saved.
This is also a governance interface. Because definitions are structured data stored in a database, every change traces to its author, timestamp, and approval state. Role-based access controls which users can modify which definitions. Governance becomes a property of the system, not a process bolted on after deployment.
The change surface per feature shrinks by 3–5x. Fewer files touched means fewer regressions, fewer merge conflicts, faster reviews. The definitions are renderer-agnostic: the same structured object renders through Vue today and could render through React, Angular, or whatever framework dominates in 2030, without changing a single definition. The application survives framework churn. That property alone makes the architecture viable for enterprise systems with 10+ year lifespans.
This isn’t theoretical. Declarative architectures run in enterprise production today: 1,300+ users across 1,000+ screens, managing 25 million documents on a single deployment. Others manage sales orders for 10,000+ products in 15+ languages.
Declarative only works with standards
A fair caveat: a declarative layer that only one vendor supports is complexity relocated, not eliminated. You trade framework lock-in for platform lock-in. The maintenance cost shifts from your codebase to the platform team’s codebase. For a single organization, that can still be a net win: fewer moving parts, faster delivery. But the architecture only reaches its full potential when it’s shared.
This is a spectrum, not an either/or. Consider how React, Angular, or Flutter amortize their rendering engines across thousands of organizations. The investment in the renderer pays off because the ecosystem is large enough to sustain it. The same logic applies to declarative application definitions: a shared schema standard means shared tooling, shared validation, shared component libraries. Maintenance costs amortize across the ecosystem.
Without that ecosystem, you build an island. Functional, but expensive to maintain and impossible to extend with third-party components. The honest position: declarative architectures deliver the most value when they converge on shared standards. That convergence is starting.
The industry is moving this direction
Google’s A2UI project, released in December 2025 under Apache 2 license, makes the pattern explicit. When an AI agent needs to present a UI across trust boundaries, A2UI doesn’t let the agent ship HTML or JavaScript. Instead, the agent sends a declarative JSON description, and the client renders it using a pre-approved component catalog.3 The client controls styling, interaction patterns, and security. The agent controls structure and data.
That design choice solves the exact problem that makes code dangerous in agentic workflows. An agent composing from a governed component catalog can’t introduce XSS vulnerabilities, because the attack surface is the catalog, not arbitrary code execution. A2UI is early-stage and evolving. But the direction matters: Google chose declarative constraints over code freedom for agent-driven interfaces because the alternative doesn’t govern.
Vercel’s trajectory points the same way. v0 generates code today, but the architecture increasingly pushes toward pre-validated component registries and design system primitives served through MCP. The generated output is React, but the generation is constrained by a curated component catalog, not arbitrary code synthesis. A bridge architecture: code as output format, governed components as the abstraction layer.
Neither A2UI nor Vercel’s registry model proves that declarative will win. What they prove is that the industry’s most infrastructure-focused companies are independently converging on the same constraint: AI should compose from validated building blocks, not generate unconstrained code.
The fork
The industry will spend its next $37 billion one of two ways: making AI write more code, or replacing code with representations AI can work with natively.
The first path is familiar. More tokens, more files, more maintenance. It scales generation without scaling governance. Every AI-written line becomes someone’s problem to review, test, secure, and upgrade. In organizations where that “someone” is a senior engineer, the path holds. In organizations where it’s a business analyst with Copilot access, it breaks.
The second path starts from a different premise: when machines become the primary authors of software, the format changes too. Not because code is bad — it’s the most powerful abstraction humans have built for controlling machines. But power without constraint is liability at scale. The first wave of AI coding tools made generation cheap. The next wave will make the output durable.
Footnotes
-
Ding et al., “LongCodeBench: Evaluating Coding LLMs at 1M Context Windows,” arXiv:2505.07897 (2025). Claude 3.5 Sonnet accuracy on LongSWE-Bench (bug-fixing task) drops from 29% to 3% as input context grows from 32K to 256K tokens. ↩
-
Veracode, “2025 GenAI Code Security Report.” 100+ LLMs tested across 80 coding tasks. 45% of test cases produced OWASP Top 10 vulnerabilities. Failure rate did not improve with model size. ↩
-
Google, “A2UI: Agent-to-User Interface,” a2ui.org (December 2025). Open-source declarative UI protocol under Apache 2 license. Early-stage, evolving specification. ↩